Introduction
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash将来自不同数据源的数据统一搜集起来,并根据需求将数据标准化输出到你所选择的目的地。如下图所示。
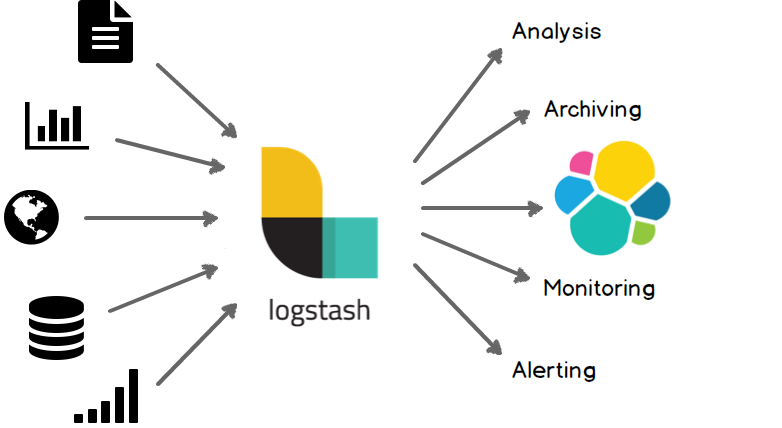
Input/Filter/Output
Logstash可以从多个数据源获取数据,并对其进行处理、转换,最后将其发送到不同类型的“存储”
输入
采集各种样式、大小和来源的数据
分布式系统中,数据往往是以各种各样的形式(结构化、非结构话)存在于不同的节点中。Logstash 支持不同数据源的选择 ,日志、报表、数据库的内容等等。可以在同一时间从众多常用来源捕捉事件。
- 文件类型
1 | input{ |
- 数据库类型
1 | input{ |
- beats
主要是接受filebeats的数据导入
1 | input { |
过滤器
实时解析和转换数据
数据从源传输到存储库的过程中,需要对不同的数据进行不同的存储,Logstash 过滤器能够解析每条记录,识别每条数据的字段内容,并将它们转换成自定义数据,以便进行处理分析计算。
Logstash 动态地转换和解析数据,支持各种格式或复杂度数据的解析:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 整体处理不受数据源、格式或架构的影响
输出
尽管 ES是logstash的常用输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
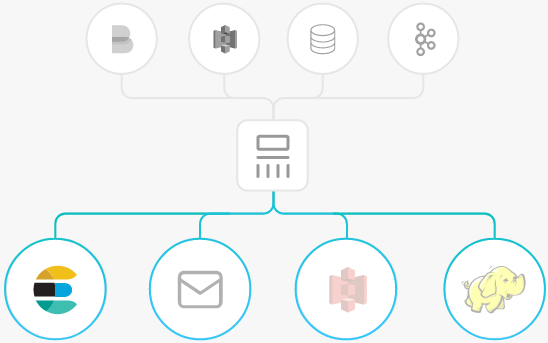
Install && config
- 安装
安装比较简单,官网直接有现成的二进制包,下载地址: https://artifacts.elastic.co/downloads/logstash/logstash-7.10.1-linux-x86_64.tar.gz
安装也比较简单,解压设置path即可使用。
本人经常使用,就写了个安装elk的脚本,需要的可以拿去使用:https://github.com/shiguofu2012/scripts/blob/master/install_elk.sh。
- 配置intput/output
Logstash配置有两个必需的元素,输入和输出,以及一个可选过滤器。输入插件从数据源那里消费数据,过滤器插件根据你的期望修改数据,输出插件将数据写入目的地。

- 接下来,允许Logstash最基本的管道,例如:
1 | [root@VM-145-82-centos ~]# logstash -e 'input { stdin {} } output { stdout {} }' |
从标准输入获取数据,输出到标准输出。
- input 从filebeat获取数据
1 | input { |
总体来讲,input/output是比较容易配置的,关键是对数据进行格式化。
- filter
正则匹配
grok 匹配非格式化字段,提取字段格式化数据,强大的文本解析工具,支持正则表达式
1 | grok { |
ip解析
1 | filter { |
解析出来的数据:
1 | { |
字段增删改
1 | filter { |
条件判断
1 | filter { |
json
1 | filter { |
Example
这里介绍一个曾经搭建的ELK日志系统。
结构比较简单,kubetnets中filebeat damonSet方式运行,搜集所有container 标准输出的日志,并传入logstash中,logstash将数据导入elasticsearch。结构图如下所示:
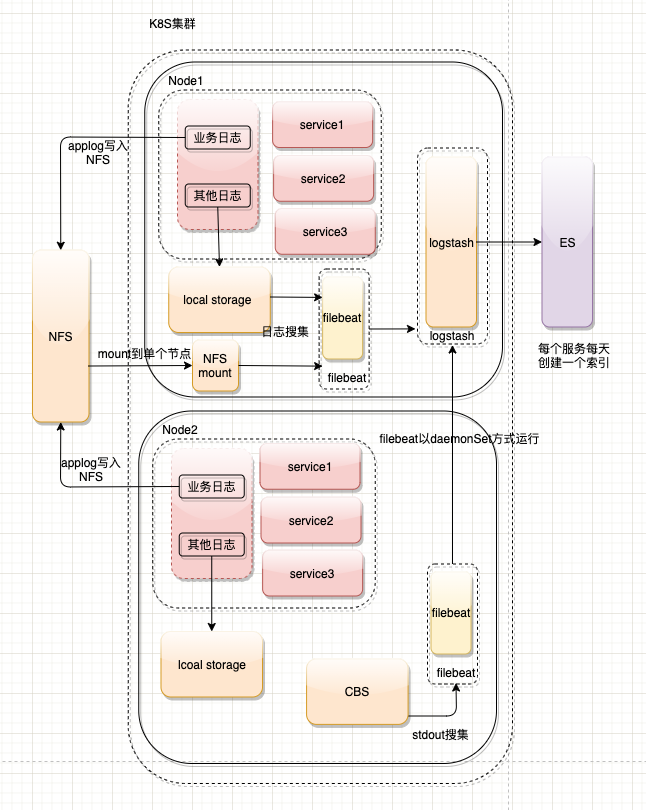
下面开始logstash的配置:
input比较简单,使用filebeat搜集日志,传入logstash
1 | input { |
output增加了几个条件判断,根据不同的字段日志类型,索引到不同的es索引中;如下所示
1 | output { |
filter 配置,不同的日志格式,输出格式化的数据
1 | filter { |
总结
总之 ,logstash具备强大的功能,将不同数据源的数据经过清洗格式化,转化为结构化的数据,存储到不同的存储单元。