数据库与缓存如何保持一致
缓存是常用的优化数据查询慢的一种方法,数据库出现瓶颈的时候,我们会给服务加上一层缓存,如Redis,命中缓存就不用查询数据库了。减轻数据库压力,提高服务器性能。
数据一致性
引入缓存后,数据出现两份,在数据变更的时候,就需要考虑缓存与数据库的一致性。
由于更新数据库与更新缓存操作 是两个步骤,在高并发的场景下,会出现什么问题呢? 我们来分析一下。
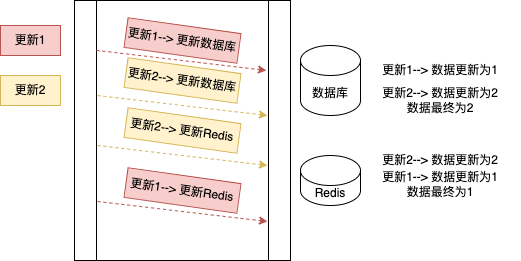
- 先更新数据库
如下图所示,高并发场景下存在数据不一致。
- 先更新缓存
同样也是会出现不一致的场景,如下图所示
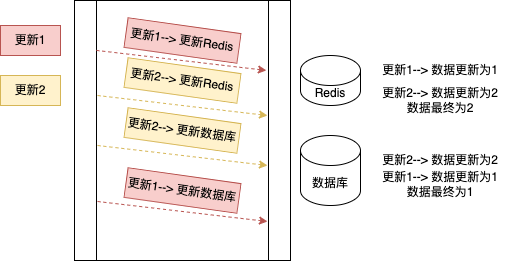
所以,无论是先更新数据库还是更新redis,都会存在数据不一致的场景,由于单个操作不是原子操作(并发导致执行数据未知),也没有事物的支持(一个成功一个失败 导致数据不一致),高并发就会存在不可预知的顺序,导致结果与预期不一致。
既然更新有问题,那缓存直接删除缓存呢?在更新的时候直接删除缓存,查询的时候 如果没有缓存就查库,并设置缓存.
如下图所示
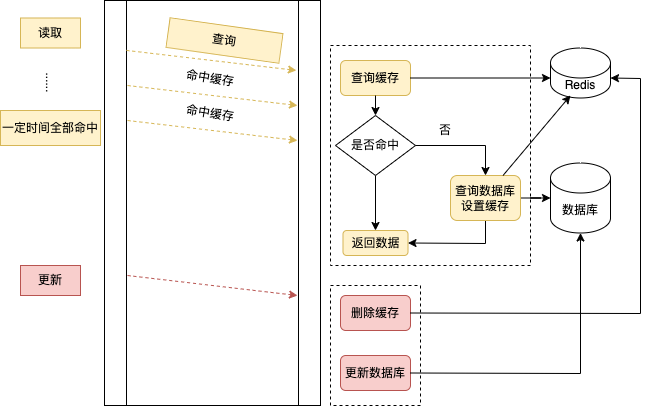
读策略步骤
- 读取缓存,命中直接返回
- 未命中,读取数据库,并设置缓存
写策略步骤
- 删除缓存
- 更新数据库
读取的逻辑比较简单,先读缓存, 再读数据库,但写策略 删除缓存与更新数据库 这两个执行顺序 看似无关紧要,谁先谁后都不影响。我们具体分析一下。
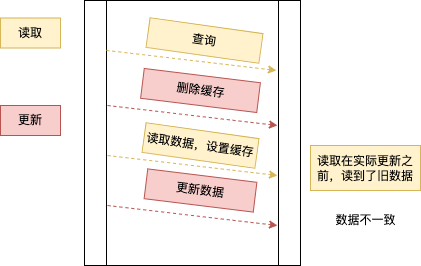
- 先删除缓存
如下图所示,读请求来先查询数据,没查到,这个时候有个更新请求,先删除缓存,之后读请求开始读取数据(数据未更新 旧数据) 并将旧数据写入缓存。更新请求更新数据库为新的数据,这时候数据不一致。
- 先更新数据库
先删除缓存有可能出现不一致的场景,那先更新数据库呢?来跟着我的思路看一下。
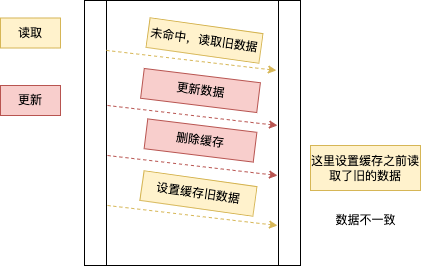
同样,一个读请求与一个更新请求,读请求先检查缓存,没数据就从数据库读取数据(这时候还是旧的数据), 在写缓存之前, 更新请求更新了数据,并执行了清理缓存的操作,这个时候,读请求的设置缓存操作执行, 就出现了不一致。
问题的关键还是 非原子操作,无事务支持,导致并发出现未知的执行顺序。
- 分布式锁
对于比较严格的场景,可以加分布式锁,将更新与删除缓存两步合为一步。也就是,数据更新可以加锁,等更新完成及缓存删除后释放锁,读请求也是加锁,发现有写锁 就等待,读锁就继续读。分布式读写锁可以解决并发导致的不一致问题。
- 延迟双删
针对「先删除缓存,再更新数据库」可以用延迟双删的操作。更新请求在删除缓存后,等待一段时间,再进行一次缓存删除操作,就可以避免缓存中缓存旧数据。
常见问题
在面试的过程中,经常会假想,在操作缓存的时候,网络抖动导致缓存操作失败,这个时候很明显数据也是不一致的。
就比如,更新完数据库,删除缓存的时候失败了,怎么保证一致?
- 重试
要保证强一致,只能多次删除,异步执行删除,失败后重试几次,一直失败可以增加告警机制配合。
也可以记录失败的key,下次读取的时候避开,总之 要保证强一致,大家应该有不少好的方法。
- MySQL binlog订阅
比较高级的一种方案,或者说比较复杂,binlog推送数据变更记录,直接删除缓存。
不过,引入一种机制,就会导致系统越来越复杂,这个就看系统的取舍了。